六边形架构
第一次看到六边形架构,是从《IDDD》这本书里看到的,当时就觉得这是和DDD相当match的架构.
稍微研究了下,发现Alistair Cockburn这篇《Hexagonal Architecture》
详细地介绍什么是六边形架构,按照惯例, A生假假地的翻译了一下.
六边形架构
作者 : Alistair Cockburn
译者 : A生
创建一个既不需要UI也不需要DB就能工作的应用程序,那样你就能针对它去运行自动化的回归测试,即使DB挂了也能继续工作,不需要任何用户参与,就能和其他应用程序连接起来.

模式: 端口与设配器 (“对象结构”)
别名 : 端口与设配器
别名 : 六边形架构
意图
允许一个应用程序平等地被用户,程序,自动化测试和批处理脚本所驱动,可被单独开发和测试于最终运行时的设备和数据库.
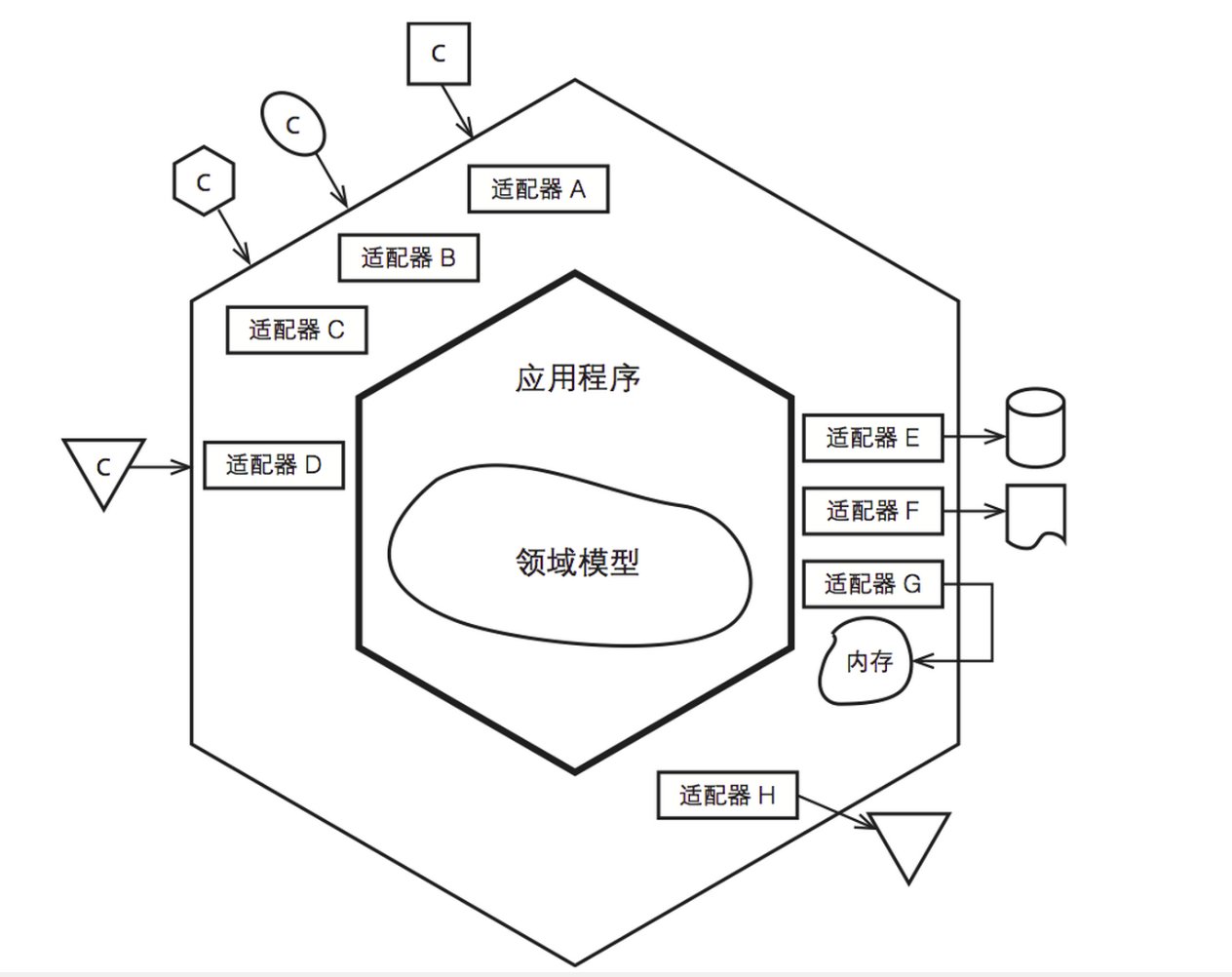
从外面世界进来的事件到达某一个端口,一个技术意义上的设配器把它转换成一个过程调用或消息后传入应用程序.应用程序幸福地忽略输入设备的本来面目.当应用程序发送某些东西出去时,它通过某个端口发送至某个设配器,去创建被接收技术方(人工或自动)所需要的适当的信号.应用程序从语义上通过适配器和各处交互,而不需要去知道设配器另一端的本来面目.
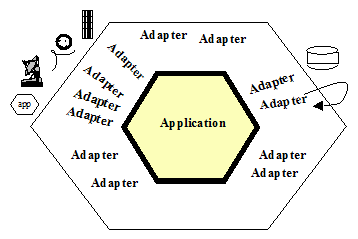
特性 1
动机
这些年来软件应用程序里最大的问题之一,就是把业务逻辑渗透在用户接口的代码里.
由此引起的问题有三部分:
- 第一,系统不能被自动化测试套件整洁地测试,因为部分需要被测试的逻辑依赖经常变化的可视化细节,如字段长度和按钮位置等;
- 因为同样的原因,它变得不可能从一个人肉使用的系统变成一个批处理的系统;
- 还是同样的原因,当系统开始受欢迎的时候,它变得困难或不可能去允许该程序被另外的程序所驱动.
在许多组织里重复的,一种尝试了的解决方案,就是创建一个分层的架构.
在那个时候去承诺,真心诚意地去承诺,没有业务逻辑会放到新的分层里.
但是,当发生了破坏承诺的时候,却没有一种机制能够检测出.
组织会发现若干年后,新的分层和业务逻辑混在一起,老问题又再次出现了.
现在想象应用程序提供的“每一片”功能,是以API(application programmed interface) 或函数调用的形式出现。
在这种情况下,当任何新的代码破坏现有可工作的功能的时候,测试或QA部门可通过运行自动化测试脚本来针对应用程序去发现问题。
业务专家可以在GUI细节最终确定之前,创建自动化测试用例,去告诉程序员,什么才是他们的工作正确完成的时候。(那些测试由测试部门来运行)。
应用程序可用“headless”模式去部署,所以只有API是有效的,其他的程序可利用它的功能——简化了整个复杂系统套件的设计,同时也许可了每一个Web上无需人介入的“business-to-business”的应用服务。
最后,自动化了功能上的回归测试,检测出了任何违背了把业务逻辑放在表现层之外的承诺。组织可以检测和修正逻辑泄露。
另外一个类似的有趣问题,什么是被认为是正常的应用程序的“另一边”,那里是应用程序逻辑被绑定在外部的数据库或设备?当数据库服务器停机或进行重大的修订或替换时,程序员就不能继续工作,因为他们的工作绑定在数据库上。这会导致延迟成本和人们会经常感觉到很糟糕。
以上2个问题看起来不是很明显的相关,但它们在自然的解决方案中却显现出了对称性。
自然的解决方案
客户端和服务器端两边的问题都是因为设计和编程上的同一个错误——业务逻辑和与外部实体交互之间的纠缠不清。
不对称的探索,不是在应用程序的“左边”和“右边“之间,而是应该在应用程序的”内部“和”外部“之间。这样的规则履行了与”内部“相关的代码不应该泄露到”外部“去。
暂时移除任何左右或上下的不对称,我们看到了应用程序通过“端口”与外部代理们沟通。
“端口”一词应会引起联想到操作系统层面的端口,任何设备都可以插入使用某种协议的端口那里。同样道理,“端口”在电子产品那,任何设备只要符合规格,都可以插入电子产品里。
端口的协议就是为了两个设备之间的会话。
这样的协议以API的形式出现。
每一个外部设备都有一个“设配器”,把API所定义的信号转换到设备所需要的,反之亦然。
一个图形化的用户接口或GUI就是一个设配器的例子,映射了一个人在API端口上的动作。
其他的设配器在同一个端口上则是自动化测试的安全带,例如FIT或Fitnesse,批处理驱动器,和任何为了应用程序和整体或网络之间沟通的代码。
在应用程序的另一边,应用程序通过与外部实体沟通来获得数据。
数据库协议就是一种经典的协议。
从应用程序的角度,如果数据库从一个SQL数据库迁移到一个扁平的文件或其他类型的数据库,通过API的转换应该没有改变。
在同一个端口上增加的设配器应该包括一个SQL设配器,一个文件设配器。
最重要的,一个去连接到“mock”数据库,一个停留在内存里和完全不依赖真正数据库的设配器。
许多应用程序只有2个端口:客户端的对话和数据库端的对话。
这让他们以不对称的形式出现,从而让看起来像是创建一个一维的,3/4/5层的架构的应用程序。
这样的图纸会有2个问题。
第一、并且是最坏的情况,人们通常不会认真地对待分层中的“边界线”。他们会让应用程序的逻辑泄露在层级边界之外,导致以上所说的问题。
第二、应用程序可能会有超过2个以上的端口,所以架构上并不对应一维的层设计。
六边形(或端口与设配器)架构通过在这种情况下注意到对称性来解决了这些问题:
一个应用程序在内部,通过某些端口与外界的东西交互。应用程序外面的东西能够尽早地去处理对称性。
六边形有意在视觉上突出
(a) 内外的对称性和相似自然的端口,摆脱了一维层视图和所有的调用,和
(b) 不同端口定义的存在数量——2,3 或4个 (4个是我最常遇到的)
六边形不是六边的是因为数字6很重要,而是允许人们进行绘制是有空间去放入他们所需要的端口和设配器,不限制于一维层次的绘制。术语“六边形架构”是来自可视化的效果。
术语“端口与设配器”拾起了部分绘制的“目的”。端口定义了有目的的会话。通常会有多个设配器对应一个端口,为了多样的技术可插入端口内。 有代表性的,它们可以包括一个电话机器应答,一个人工应答,一个按键式电话,一个图形化人机界面,一个测试装置,一个批处理驱动器,一个http接口,一个程序到程序的接口,一个mock(内存内)数据库,一个真正的数据库(可能有不同的数据库用于开发。测试和实际使用)。
在应用程序里,左右不对称将再次带出来,无论如何,这个模式的主要目的是集中于内外不对称,从应用程序的角度,假装短暂地识别所有的外面组件。
结构
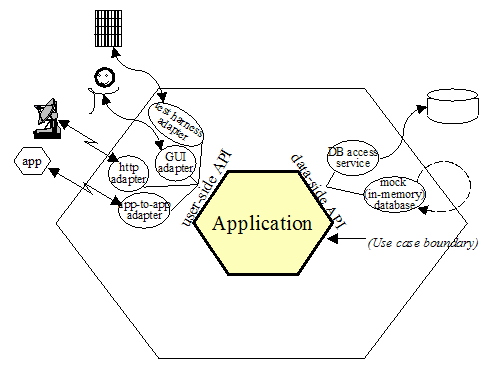
特性 2
特性2显示了一个应用程序有着2个活动端口和用于同一个端口多个设配器。那2个端口分别是应用程序控制方面和数据检索方面。这样的绘制显示出应用程序可以被平等地驱动于:一个自动化、系统级别的回归测试套件,一个人类用户,一个远程的http应用程序,或者另一个应用程序。在数据方面,应用程序从外部数据库解耦,可以被配置运行在一个内存内的Oracle,或“mock”,数据库替换者;或者它可以运行在针对测试的或运行时的数据库。应用程序功能上的规格,或许在用例内,是针对与六边形内部的接口,而不是针对任何一个外部的技术可能用到的接口。
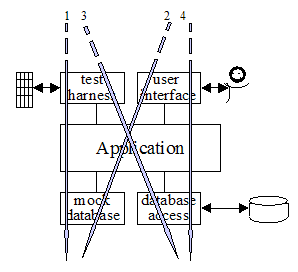
特性 3
特性3显示出同一个应用程序对应一个三层架构绘制。每一个端口简化到只有2个适配器。这样的绘制趋势于去显示,多个适配器怎样去适应于顶层和低层,和在开发系统中被用到的,多个适配器之间的序列。编号的箭头显示出一个团队和应用程序可能会用到的次序:
- 用于被应用程序驱动的一个FIT测试设备和用着取代真正数据库的mock(内存内)数据库;
- 增加一个GUI到应用程序,仍然跑在mock数据库。
- 在集成测试里,针对于一个真正包含测试数据的数据库,运行自动化测试脚本(如从Cruise Control)去驱动应用程序。
- 真正地去使用,一个人通过应用程序去访问真正的数据库。
样例代码
幸运地可以通过FIT的文档,一个最简化应用程序去演示端口与适配器。它是一个简单的折扣计算的应用程序:
1 | discount(amount) = amount * rate(amount); |
在我们的程序里,amount会来自用户和rate会来自一个数据库,所以那里会有2个端口。
我们实现它们在以下步骤:
- 测试取代mock数据库的一个固定的rate
- 然后是GUI
- 然后是一个可被切换到真正数据库的mock数据库
感谢在IHC的Gyan Sharma 提供这个例子的代码。
步骤1: FIT App constant-as-mock-database
首先我们创建测试用例通过一个HTML table(看FIT文档如下):
| TestDiscounter | |
| amount | discount() |
| 100 | 5 |
| 200 | 10 |
注意列名会变成class和function名字在我们的应用程序里。
FIT包括了摆脱这种“programmerese”的道路,但是为了这篇文章会简单地把它们放进来。
知道了那些会是测试的数据,我们创建用户边的设配器,来自FIT里的ColumnFixture如下:
1 | import fit.ColumnFixture; |
实际上那里的所有都是到设配器的,目前为止,测试可从命令行里运行(看FIT的书会有你所需要的路径)。我们使用这个:
1 | set FIT_HOME=/FIT/FitLibraryForFit15Feb2005 |
FIT 生产出一个导出的文件,通过颜色告诉我们那些测试通过了(或者失败,唯一我们在过程中从那里打错了)
在这个点上的代码已经准备好去check in,集成在Cruise Control或你自己的自动化构建机器里,包括在构建-测试套件里。
步骤2: UI App constant-as-mock-database
我会让你去创建属于你自己的UI和让它驱动Discounter应用程序,因为代码放在这里有点过长,某些关键的代码如下:
1 | ... |
在这个点上的代码可以去被演示和回归测试。用户端的设配器都已运行中。
步骤3: (FIT or UI) App mock database
去创建一个可替换的数据库端的设配器,我们为一个仓储创建一个“接口”,一个“RepositoryFactory” 会生产出要么模拟数据库、要么真正的服务的对象,在内存里去模拟数据库。
1 | public interface RateRepository |
挂钩这个设配器到Discounter应用程序内,我们需要更改下应用程序自身,去接受使用一个repository设配器,和让(FIT / UI)用户端的设配器传入repository去使用(real or mock)到应用程序的构造函数里。
这里有已更改的应用程序和一个FIT设配器传入一个模拟的repository。
(FIT设配器的代码,选择是否传入到模拟或真实repository的设配器里,在没有增加太多新的信息情况下有点过长,所以我在这里省略的那个版本)
1 | import repository.RepositoryFactory; |
那样就包括了实现六边形架构的最简单的版本。
另外一个不同的实现,使用Ruby和Rack为了浏览器使用,详情:
https://github.com/totheralistair/SmallerWebHexagon
应用程序指南
左右不对称
端口和设配器模式是故意把所有的端口都写上去像是从根本上是相似的。那样的假装在架构层面是有用的。
在实现阶段,端口和设配器显示出2种风味,我将其称之为“主要的”和“次要的”,理由很快会揭晓。它们可称之为“驱动”设配器和“被驱动”设配器。
警觉的读者会注意到所有已给的例子里,FIT fixtures是用了左边端口而mock在右边。
在三层的架构里,FIT 坐落在顶层而mock坐落在底层。
相关的主意是来自“主角”和“次角”的例子。“主角”是驱动了应用程序(改变静止的状态和执行某个已知的功能)。“次角”是被应用程序所驱动的,无论是从中获取应答还是仅仅是通知。“主角”和“次角”的差别是在于谁触发了或者是负责了会话。
FIT是代替主角的自然测试设配器,从框架设计成读取一个脚本和驱动应用程序开始。
mock是代替了“次角”的自然测试设配器,从被设计成从应用程序里去应答查询和记录事件开始。
这些观察带领我们服从系统的用例上下文图,和在六边形的左边(或顶层)去绘制“主要端口”和“主要适配器”,在六边形的右边(或底层)去绘制“次要端口”和“次要适配器”。
主次要端口和设配器之间的关系,和他们在FIT和mock的各自实现,记在脑子里是有用的,但应该是用来作为使用端口和设配器架构的结论,而不是简化之。
实现端口和设配器的最终好处从一个完全隔离模式敏捷地去运行应用程序。
用例和应用程序边界
使用六边形架构模式是有用地去加强,编写用例的首选模式。
编写用例通常会犯的错误是,在每个端口外面包含了亲密的技术知识。
在行业里这种用例获得了众所周知的坏名声,变得冗长,难读,沉闷,易碎,维护昂贵。
理解端口和设配器模式,我们可以看到用例一般应该写在应用程序边界内(六边形内部),
去指定被应用程序所支持的功能和事件,不去管外部的技术。
这样用例是简短,易读,更少维护成本,和在时间上更加稳定。
多少端口?
到底什么是或不是端口,很大程度上只是口味的问题。
在极端的情况下,每一个用例只有自己的端口,为了许多的应用程序提供了上百个端口。
另外的一种选择,可以想象把所有的主要端口和次要端口融合在一起,到那时3只有2个端口,左边的和右边的。
没有最好只有更好。
已知应用的天气预报系统有着4个自然的端口:天气反馈,管理员,通知用户,用户数据库。
咖啡售卖机的有4个自然的端口:用户,包括食谱和价格的数据库,售卖机,和硬币箱子。
医院的药物系统可能有3个:一个给护士,一个给药方数据库,一个给控制药物分配器。
选择“错误”数量的端口数不见得会有任何特殊的坏处,所以保持一种直觉即可。
我倾向于选择少量的数目,2,3或4,如上所述和已知应用。
已知应用
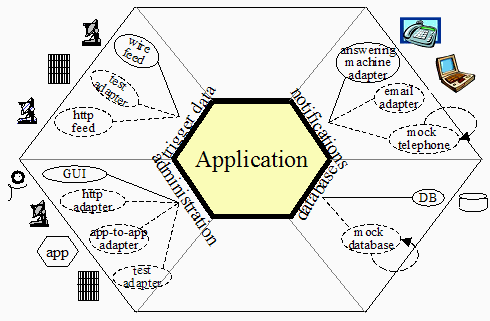
特性 4
特性展现一个有着4个端口并且每个端口都有多个设配器的应用程序。
这是从一个应用程序衍生出的监听来自国家天气服务的警报,关于地震,龙卷风,火灾
和水灾。和通知人们通过他们的电话或电话对讲机。
在我们讨论这个系统的时候,这个系统的接口已确认,从“技术,连接的目的”上讨论过。那里有一个接口为了接收电线上的触发数据,一个为了把通知数据发送到对答的机器上,一个GUI实现的管理接口,和一个获取用户数据的数据库接口。
人们正在努力,因为他们需要从天气服务增加一个http接口,一个email接口给他们的用户,和他们不得不寻找一种方式可以为了不同的客户采购偏好,绑定和解绑他们增长着的应用程序套件。他们害怕停留在一个维护和测试的噩梦里,因为他们不得不实现,测试和维护所有独立的组合和排列的版本。
他们修改了设计,在系统接口上根据“目的”而不是根据“技术”去架构,让技术通过设配器变得可以替换(所有方面的)。
他们立马提高了速度去包含http订阅和email通知(新的设配器通过虚线绘制出来)。
通过APIs让每个应用程序在headless模式下运行,他们可以增加一个 app-to-add 的设配器和解除绑定应用程序套件,按需连接子应用程序。
最后,让每一个应用程序可完全独立的执行,通过内置的测试和mock设配器,他们获得了敏捷的通过独立的自动化测试脚本去回归测试他们的应用程序。
Mac, Windows, Google, Flickr, Web 2.0
早在1990时,MacIntosh应用程序如文档处理软件就需要有API驱动的接口,所以应用程序和用户编写的脚本就可以访问应用程序的所有的功能。Windows桌面软件有着同样的能力。(我没有对应的历史知识去说谁先出现,反正那也不是重点)
如今(2005)web软件的趋势是发布一个公共API去让别的软件直接的访问那些APIs。
虽然,那可能会通过google map去发布一些犯罪的数据,或者创建web应用程序包括Flickr在内的相片存档和注释的能力。
所有的这些例子都是关于把“主要的”端口的API可视化, 我们看不到任何信息在次要端口。
Stored Outputs
Willem Bogaerts在C2 wiki上写下这个例子:
“我遇到过类似的事情,但是主要是因为我的应用程序层有很强的趋势去变成一个电话切换板去管理它不应该去做的事情。我的应用程序产生输出,显示给用户和有可能会去保存好它。我主要的问题是你不需要常常去储存它。所以我的应用程序产生输出,不得不缓存它和展现给用户。然后,当用户决定要保存导出的数据时,应用程序清空缓冲和真正的保存它。
我一点都不喜欢这个,于是我想出了一个解决方案:有一个带存储功能的展现控制器。现在应用程序不再需要管道输出到不同的方向,只是简单地输出到展现控制器。展现控制器缓冲了结论和给用户去保存它的可能性。
传统的架构分层强调“UI”和“存储”是不同的。
端口和设配器模式架构可以再简化输出到简单的“输出”。
”
来自C2-wiki的匿名例子
“在我做过的一个项目里,我们使用“真音响设备”的系统隐喻。
每一个组件定义了接口,每一个接口都有不同的目的。
我们几乎可以通过连线和设配器,没有限制的把组件们连接在一起
”
分布式,大团队开发
这个还在实验阶段的使用和还不能恰当地评估这个模式的使用情况。
无论如何,那个很有意思去考虑的。
不同位置的团队们全去构建六边形架构,用着FIT和mocks,所以应用程序和组件可以独立模式下去测试。CruiseControl每半个小时去运行构建和使用FIT+mock的组合去运行所有的应用程序。因为应用程序子系统和数据库已完整地,替换成mock和测试数据库了。
独立的开发UI和应用程序逻辑
这个还在早期的实验阶段的使用和还不能恰当地评估这个模式的使用情况。
无论如何,那个很有意思去考虑的。
UI设计是不稳定的,因为它们还未定好是那一种驱动的技术或隐喻。
后端服务架构没有定好,事实上它可能在半年内经历过几次改变。
尽管如此,项目却是正常地启动和时间是滴答作响的。
应用程序团队创建FIT测试和mocks去隔离他们的应用程序,创建可测试的,可演示的功能展示给他们的用户。
当UI和后端服务最终决定时,它“一个直接的”增加那些元素到应用程序里。
开始学习怎样实现它。(或你自己尝试下和写邮件给我)
(A生注: 相关模式、感谢和其他引用就不再翻译拉~~ :) )
Related Patterns
Adapter
The ‘’Design Patterns’’ book contains a description of the generic ‘’Adapter’’ pattern: “Convert the interface of a class into another interace clients expect.” The ports-and-adapters pattern is a particular use of the ‘’Adapter’’ pattern.
Model-View-Controller
The MVC pattern was implemented as early as 1974 in the Smalltalk project. It has been given, over the years, many variations, such as Model-Interactor and Model-View-Presenter. Each of these implements the idea of ports-and-adapters on the primary ports, not the secondary ports.
Mock Objects and Loopback
“A mock object is a “double agent” used to test the behaviour of other objects. First, a mock object acts as a faux implementation of an interface or class that mimics the external behaviour of a true implementation. Second, a mock object observes how other objects interact with its methods and compares actual behaviour with preset expectations. When a discrepancy occurs, a mock object can interrupt the test and report the anomaly. If the discrepancy cannot be noted during the test, a verification method called by the tester ensures that all expectations have been met or failures reported.” — From http://MockObjects.com
Fully implemented according to the mock-object agenda, mock objects are used throughout an application, not just at the external interface The primary thrust of the mock object movement is conformance to specified protocol at the individual class and object level. I borrow their word “mock” as the best short description of an in-memory substitute for an external secondary actor.
The Loopback pattern is an explicit pattern for creating an internal replacement for an external device.
Pedestals
In “Patterns for Generating a Layered Architecture”, Barry Rubel describes a pattern about creating an axis of symmetry in control software that is very similar to ports and adapters. The ‘’Pedestal’’ pattern calls for implementing an object representing each hardware device within the system, and linking those objects together in a control layer. The ‘’Pedestal’’ pattern can be used to describe either side of the hexagonal architecture, but does not yet stress the similarity across adapters. Also, being written for a mechanical control environment, it is not so easy to see how to apply the pattern to IT applications.
Checks
Ward Cunningham’s pattern language for detecting and handling user input errors, is good for error handling across the inner hexagon boundaries.
Dependency Inversion (Dependency Injection) and SPRING
Bob Martin’s Dependency Inversion Principle (also called Dependency Injection by Martin Fowler) states that “High-level modules should not depend on low-level modules. Both should depend on abstractions. Abstractions should not depend on details. Details should depend on abstractions.” The ‘’Dependency Injection ‘’pattern by Martin Fowler gives some implementations. These show how to create swappable secondary actor adapters. The code can be typed in directly, as done in the sample code in the article, or using configuration files and having the SPRING framework generate the equivalent code.
Acknowledgements
Thanks to Gyan Sharma at Intermountain Health Care for providing the sample code used here. Thanks to Rebecca Wirfs-Brock for her book ‘’Object Design’’, which when read together with the ‘’Adapter’’ pattern from the ‘’Design Patterns’’ book, helped me to understand what the hexagon was about. Thanks also to the people on Ward’s wiki, who provided comments about this pattern over the years (e.g., particularly Kevin Rutherford’s http://silkandspinach.net/blog/2004/07/hexagonal_soup.html).
References and Related Reading
FIT, A Framework for Integrating Testing: Cunningham, W., online at http://fit.c2.com, and Mugridge, R. and Cunningham, W., ‘’Fit for Developing Software’’, Prentice-Hall PTR, 2005.
The ‘’Adapter’’ pattern: in Gamma, E., Helm, R., Johnson, R., Vlissides, J., ‘’Design Patterns’’, Addison-Wesley, 1995, pp. 139-150.
The ‘’Pedestal’’ pattern: in Rubel, B., “Patterns for Generating a Layered Architecture”, in Coplien, J., Schmidt, D., ‘’PatternLanguages of Program Design’’, Addison-Wesley, 1995, pp. 119-150.
The ‘’Checks’’ pattern: by Cunningham, W., online at http://c2.com/ppr/checks.html
The ‘’Dependency Inversion Principle’‘: Martin, R., in ‘’Agile Software Development Principles Patterns and Practices’’, Prentice Hall, 2003, Chapter 11: “The Dependency-Inversion Principle”, and online at http://www.objectmentor.com/resources/articles/dip.pdf
The ‘’Dependency Injection’’ pattern: Fowler, M., online at http://www.martinfowler.com/articles/injection.html
The ‘’Mock Object’’ pattern: Freeman, S. online at http://MockObjects.com
The ‘’Loopback’’ pattern: Cockburn, A., online at http://c2.com/cgi/wiki?LoopBack
‘’Use cases:’’ Cockburn, A., ‘’Writing Effective Use Cases’’, Addison-Wesley, 2001, and Cockburn, A., “Structuring Use Cases with Goals”, online at http://alistair.cockburn.us/crystal/articles/sucwg/structuringucswithgoals.htm