Cucumber : 行为驱动指南

为什么要用Cucumber?
Cucumber是一个实现BDD(行为驱动指南)的工具,为什么要使用它呢?
软件始于一个想法。
但是,如果一个开发人员误解的一个想法,然后花了2周的一次迭代实现了它,那么他不仅仅浪费了2周的时间,还引入一些误解最初想法的概念和功能,破坏了代码的完整性。
这就是cucumber要解决的问题,作为一种过滤器,过滤那些被误解的想法。
自动化验收测试
单元测试确保你正确地编写软件,验收测试确保你编写正确地软件。
通用语言
Cucumber为存在语言分歧的双方,提供可以发现和使用通用语言的场所。
活的文档
用Cucumber编写的文档,是可执行的规格说明(executable specification),
Overview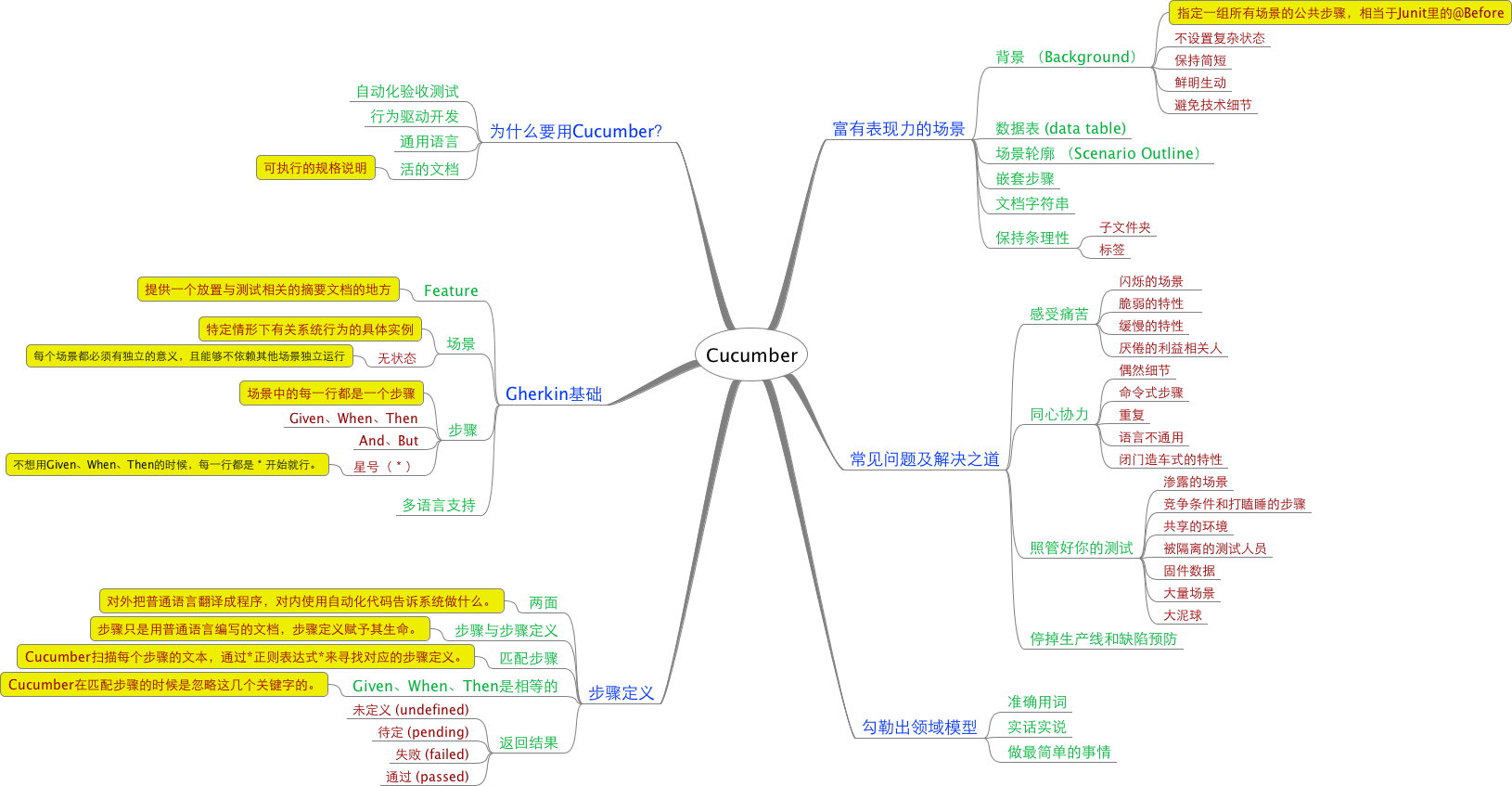
Gherkin基础

Gherkin是一种DSL,是可执行的规格说明。它以.feature为后缀名,以简单文本格式保存。
关键字
- Feature
- Background
- Scenario
- Scenario outline
- Scenarios (or examples)
- Given
- When
- Then
- And (or But)
- | (用来定义表格)
- “”” (定义多行字符串)
(注释)
模拟运行
$ cucumber test.feature --dry-run
解析不执行
Feature
每一个Gherkin文件都以Feature关键字开头。
它只是提供一个地方,放置与测试相关的摘要文档。
合法的Gherkin必须包含以下其中一个元素:
- Scenario
- Background
- Scenario outline
场景
场景是特定情形下有关系统行为的具体实例,所有的场景会和起来就是这个特性期望的行为。
无状态
每个场景都必须有独立的意义,且能够不依赖其他场景独立运行。
多语言支持
Cucumber支持多国语言来编写 , 以下目录显示所有支持的语言
$ cucumber --i18n help
步骤
场景中的每一行都是一个步骤
Given、When、Then
Given 用来建立场景发生的上下文
When 以某种方式与系统交互
Then 检查交互的结果是否符合预期
And、But
使用And/But 可以为Given、When、Then增加更多的步骤。
星号(*)
不想用Given、When、Then的时候,每一行都是*开始就行。
注释(#)
#comment sth
步骤定义
步骤定义在业务领域和编程领域的边界上。
两面
对外把普通语言翻译成程序,对内使用自动化代码告诉系统做什么。
步骤与步骤定义
步骤只是用普通语言编写的文档,步骤定义赋予其生命。
匹配步骤
Cucumber扫描每个步骤的文本,通过正则表达式来寻找对应的步骤定义。
例子
1 | Feature: 网页搜索 |
1 | /** |
正则表达式
1 | ("^输入 \"(.*?)\"$") |
捕获组(A|B): 用()包围的那部分,加上|可多选分支
点号(.): 匹配单个任意字符
星号(*): 任意多次
加号(+): 至少一次
问号(?): 0或1次
字符组:
\d 代表数字,[0-9]
\w 代表单词字符 [A-Za-z0-9]
\s 代表空白字符 [\t\r\n]
\b 代表单词边界,任何不是单词字符的都是单词边界
大写则是代表相反结果,如\D表示任意非数字字符
非捕获组就是正则表达式之外的那部分。如例子里的“输入”。
锚点
步骤 以 ^开头 $结尾 ,保持紧凑。
Given、When、Then是相等的
Cucumber在匹配步骤的时候是忽略这几个关键字的。
返回结果
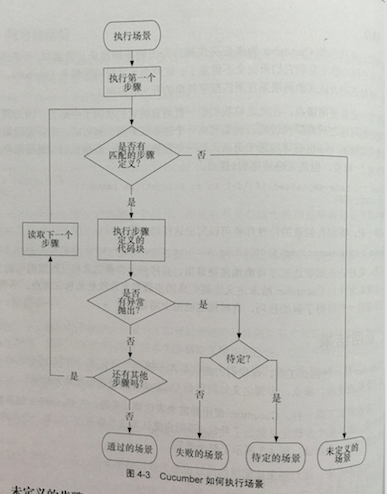
- 未定义 (undefined)
- 待定 (pending)
- 失败 (failed)
- 通过 (passed)
富有表现力的场景
背景 (Background)
背景: 指定一组所有场景的公共步骤,相当于Junit里的@Before
- 不设置复杂状态
- 保持简短
- 鲜明生动
- 避免技术细节
1 | Feature: Multiple site support |
数据表 (data table)
1 | | start | eat | left | |
数据表本质上是一个二维数组,是Gherkin的一个重要特性。
使用raw()方法可以获取原始格式,使用diff!可以比较数据表。
场景轮廓 (Scenario Outline)
1 | Scenario Outline: eating |
场景轮廓用于遵循同样步骤的场景,使用它的前提是要有一个实例表(Examples,可以用Scenarios代替),通过它的占位符是尖括号 (<..>),
将实例表的每一行转换成一个场景再执行。
其中一个优点就是:你能够清楚地看到实例中遗漏的东西。
通过使用更大的占位符,可以有效地减少重复的内容。
但是这一切的底线是不能影响可读性,最终目的是为了能够解释自己。
嵌套步骤
1 | When /^I make all my stuff shiny$/ |
通过steps %{}可以把一些步骤归纳成更抽象的步骤,但过度使用就会带来不必要的复杂性。
文档字符串
1 | """ |
1对的三个双引号”””之间,可以把一大堆文本(html/json/*)放置在内。
保持条理性
使用子文件夹和标签可以更有条理的管理特性,标签用@开头,可以通过命令行运行某个子文件夹或标签里的内容。
1 |
|
常见问题及解决之道
感受痛苦
闪烁的场景
偶尔失败,随机失败的场景为闪烁的场景。
解决它需要研究代码,弄清为什么会发生。
通常有以下问题所导致:
- 共享的环境
- 渗露的场景
- 竞争条件和打瞌睡的步骤
脆弱的特性
脆弱的特性极易被破坏。特性脆弱时,在测试套件或主代码库的某个部分做些必要的修改会破坏明显不相关的场景。
脆弱的特性通常由以下问题之一所引发。
- 固件数据
- 重复
- 渗露的场景
- 被隔离的测试人员
缓慢的特性
缓慢的特性通常由下列问题的某种组合引发。
- 竞争条件和打瞌睡的步骤
- 大量场景
- 大泥球
厌倦的利益相关人
一开始就同业务利益相关人建立正确的协作关系。如果他们觉得自己太忙,没时间帮你准确理解他们想要的东西,那么你面对的是一个更深层的团队问题,Cucumber爱莫能助。
但另一方面,许多团队开始时倒是有热心主动的利益相关人,可团队却浪费了Cucumber带来的建立这种协作关系的机会。如果测试人员或开发人员独自编写特性,他们就难免使用技术术语,这样利益相关人在阅读的时候会觉得自己被边缘化了。
这会变成恶性循环:利益相关人本来可以帮助你使用对他们有意义的语言编写特性,但随着兴趣渐失,他们花在这上面的时间会越来越少。不知不觉中,特性就沦为纯粹的测试工具了。
这一痛苦症状通常由下列问题的某种组合引发。
- 偶然细节
- 命令式步骤
- 重复
- 语言不通用
- 闭门造车式的特性
同心协力
Cucumber的特性正是Gojko Adzic 所说的活文档(living documentation)。这一术语恰如其分地总结了使用Cucumber的两大好处。
活的:能自动测试系统,以便你可以安全地工作。
文档:便于大家有效地沟通系统的当前行为和预期行为。
偶然细节
像密码这种在场景中提及但实际上与场景的目标毫无关系的细节,我们称之为偶然细节(incidental detail) 。这种不相关的细节使得场景很难阅读,而这又会让利益相关人对阅读场景失去兴趣。
避免偶然细节
编写场景的时候,尽力避免被已有的步骤定义所左右,只管用直白的语言把你希望发生的事情确切地写下来即可。
事实上,尽量不要让程序员或测试人员独自编写场景。让非技术的利益相关人或者分析师从纯粹以业务为中心的角度出发编写每个场景的初稿,或者最理想的情况是与程序员结对,从而分享他们的构思模型。
有了工程意义上设计精良的支持层,你便可以信心百倍地快速编写新的步骤定义来配合场景的表达方式。
命令式步骤
命令式编程是指使用一个命令序列,让计算机按特定的次序执行它们。
Ruby就是命令式语言的例子:你把程序写成一系列的语句,Ruby按顺序每次执行其中的一条语句。
声明式编程则告诉计算机应该做什么(what),而并不精确指明如何(how)去做。
CSS就是声明式语言的例子:你告诉计算机希望Web页面上的各种元素如何呈现,剩下的让计算机去处理。
Gherkin当然是命令式语言。Cucumber按照你编写的顺序依次执行场景中的每个步骤,每次执行一步。但这并不意味着这些指令读起来要像装配组合家具的说明书一样。
最严重的是,使用这样的泛化步骤定义写出的场景无法创建出场景的领域语言。
Gherkin特性中在命令式风格和声明式风格之间并没有明确的界线。
相反,这是一个连续的频谱,每个场景中每个步骤在频谱上的正确位置取决于许多方面:你所描述的系统领域,你所构建的应用类型,程序员的领域知识,以及非技术利益相关人对程序员的信任水平。
如果利益相关人希望在特性中看到许多细节,这或许表明你需要努力改善这一信任,但也可能说明你们开发的系统就是需要详述很多细 节的。
重复
DRY原则 (Don't Repeat Yourself)指出,任何概念的定义应当在代码中出现且仅出现一次。
这是一个了不起的目标,因为你如果必须对系统的行为做出修改,肯定希望只在一个地方修改,同时又对改动很有信心,相信它会一致地应用于整个代码库。如果那种行为散落在代码的多处定义中,不但你自己无法全部找到它们,很可能在你之前因为别人也不能全部找到,结果那些定义已经彼此不一致了,谁愿意这样呢?
然而,在你用实例驱动代码的时候,我相信有另外一个原则优于DRY:实例应当讲出一个好故事。实例是给未来的程序员(包括你自己,如果在3个月以后你会回来修改这段代码的话,那时你已经忘记它做的是什么了)提供指导的文档叙述。
假设你读这样一本书:里面所有的情节和人物都按照DRY原则给抽干了,一切只出现在脚注或附录中。所有的人物描述、情节元素、潜台词等都被仔细抽取出来,做成交叉引用的章节。如果你是在读百科全书,这非常好,但如果你想投入到故事流中,弄清楚发生的事情,这样就不太合适了。你会在书中无休止地来回翻阅,而且很快会忘记故事看到哪儿了。借用一个古老的玩笑,字典里面密密麻麻全是情节,但在”情节”的行进中,它们至少解释了所有的单词。
有些人把这称为DAMP(Descriptive and Meaningful Phrases)原则:描述性且有意义的叙述。编写实例的时候,可读性压倒一切,于是DAMP高于DRY。
语言不通用
我们讨论的是开发一种通用语言,因为这是一个持续进行的过程。这一开发过程需要我们工作上的投入。真正做到彼此倾听并且就使用的词语达成一致是需要努力的,而坚持这种约定也是需要纪律的。
然而,回报是巨大的。使用通用语言的团队犯错更少,且更能享受工作的乐趣,因为他们能有效地沟通工作内容。
不重视通用语言价值的团队将会粗枝大叶地使用场景中的语汇,从而丧失在团队中专注技术和专注业务的双方之间构筑坚固桥梁的宝贵机会。那时,如果你试图纠正别人或澄清术语,带给人的感觉只会是吹毛求疵。
闭门造车式的特性
人们会觉得Cucumber是一种技术性较强的工具。它从命令行运行,特性文件也被设计成需要与被测代码一道签入版本控制系统。然而它却以帮助提高团队的业务利益相关人对开发过程的控制感为目标。当测试和开发尽情把特性塞入版本控制的时候,团队中其他人会觉得他们的文档被锁进了柜子,而他们却没有钥匙。
你只需要坚持做到同业务利益相关人一起坐下来协作编写场景,就足以收获Cucumber至少一半的好处。这一过程所激发的交谈会解开太多太多的潜在bug或时间延误,即便你从不打算将特性自动化,也已经收获颇丰了。
照管好你的测试
自动化特性的好处在于你可以把它们作为活文档来长期信赖,因为你会将每一个场景都用于检查产品代码,以确保它们仍然有效。
对于同代码打交道的程序员来说,这还有另一件好处:在他们开发系统的时候,那些测试可以充当安全网,对任何破坏已有行为的错误都给出警告。
渗露的场景
Cucumber场景本质来说是状态转换,如果2个测试之间存在状态依赖,那就发生了渗露(leak)
每个场景都是独立的,可以确保场景将系统置于干净的状态,然后再添加自己的数据。
竞争条件和打瞌睡的步骤
端对端的测试里,终究会遇到竞争条件和沉睡的步骤的问题。
一种粗糙的解决方法就是引进固定时长地停顿或睡眠。
如果一定要作出选择,我们宁可要缓慢但可靠的测试,也不要更快但不可靠的测试。
但如果熟知系统工作原理,就可以利用系统隐含的线索让测试知道何时能够安全地前进。
共享的环境
对单一环境的共享使用会对数据库这种紧张地资源造成沉重且不稳定的负荷,从而造就不可靠的测试。
解决之道在于“一键式搭建系统”
被隔离的测试人员
测试人员不应该被看作二等公民,应该与开发人员结对,创造结构更清晰,更稳健的测试套件。
这样测试人员就可以解放自己,去做更有趣、更有创造性的探索性测试。(exploratory testing)
固件数据 (fixture data)
固件数据,即使开始时相对精简,时间长了体积也会只增不减。随着越来越多的场景开始依赖这些数据,且每个场景都要对它们做一点特别的处理,固件数据的体积会越来越大,复杂度也会越来越高。
当你为了某个场景对数据做点改动,结果却使其他场景失败时,你将开始感受到脆弱的特性的痛苦。
有这么多不同的场景依赖于固件数据,你会倾向于糊上更多的数据,因为这比修改已有的数据更加安全。某个场景失败时,你很难清楚系统中的哪一团数据可能跟失败相关,诊断起来也更加困难。
我们认为固件数据是一种反模式(antipattern)。
我们更倾向于使用之前介绍过的测试数据构造器,比如FactoryGirl ,那样可以让测试本身从内部创建相关数据,而不是让这些数据淹没在一大团混乱的固件数据集合中。
大量场景
数量巨大的特性很难组织得井井有条,可通过子文件夹和标签来合理组织。
另外一种方法就是考虑下移一些到单元测试里。
大泥球
软件架构一团糟得情况叫做大泥球(Big Ball of Mud)。
Alistair Cockurn的端口和适配器(port and adapter)架构是一种让系统容易测试的架构,建议使用.
勾勒出领域模型
任何面向对象程序的核心都是领域模型。
基于领域模型工作,而不是用户界面上的各种花样。
一旦有了能够反映我们对系统理解的领域模型,给它包上漂亮的外衣是很容易的事情。