NoSQL 精粹

Martin Fowler和Pramond(《数据库重构》作者)联合出品的这本书,为了我们如何看待、使用NoSQL数据库,提供了一个很好的起点。
为什么要用NoSQL?
关系型数据库有很多优势,但绝非完美。对开发者来说,最令他们失望的就是:
关系模型和内存中的数据结构存在差异,即 “阻抗失谐”
另外,关系型数据库在集群的环境中使用的成本较高,不适用于21世纪的互联网公司。
NoSQL作为无模式、非关系数据库而出现,有效的解决以上问题。
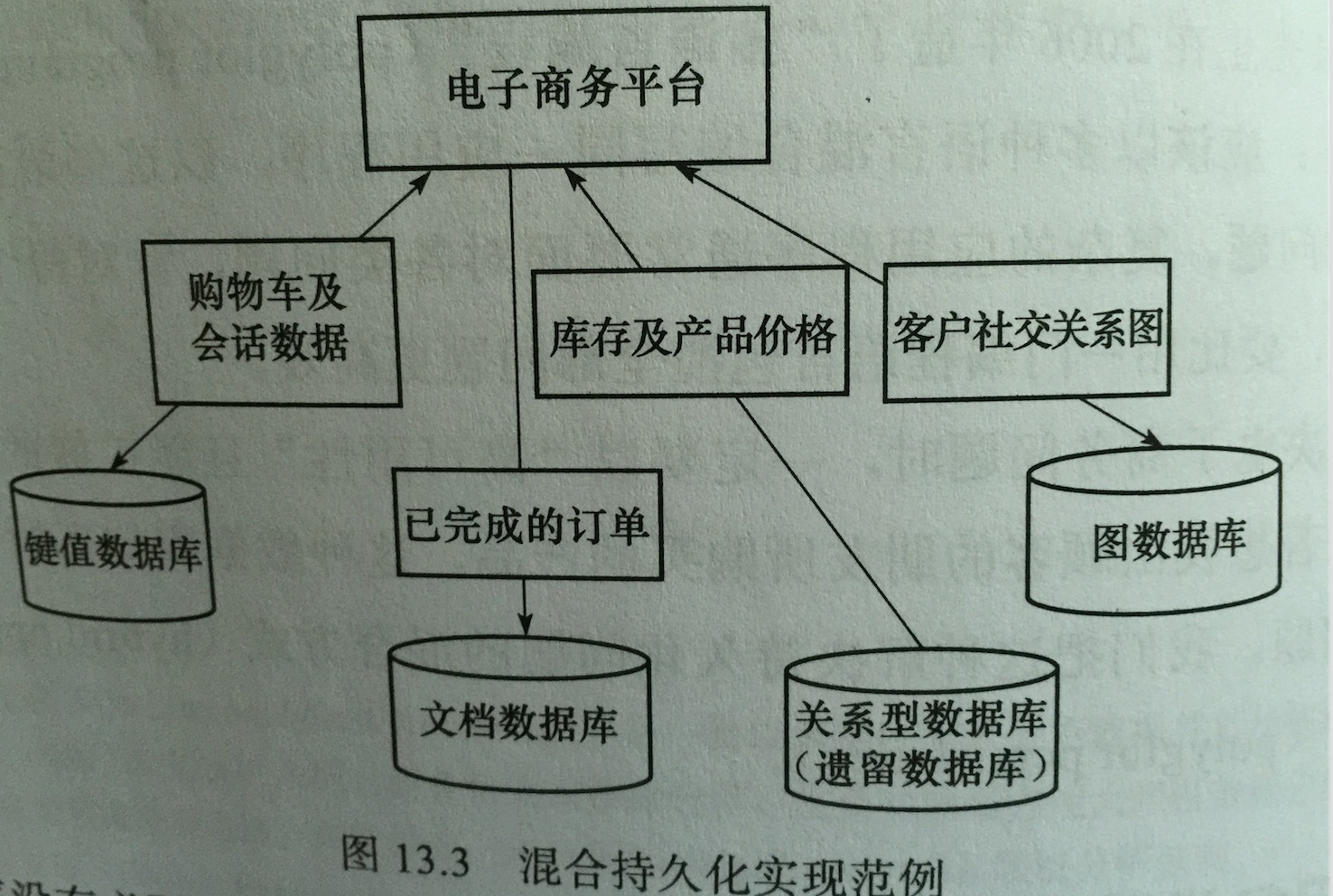
为关系型数据库做了有益的补充,让混合持久化成为了当今的趋势。
数据模型
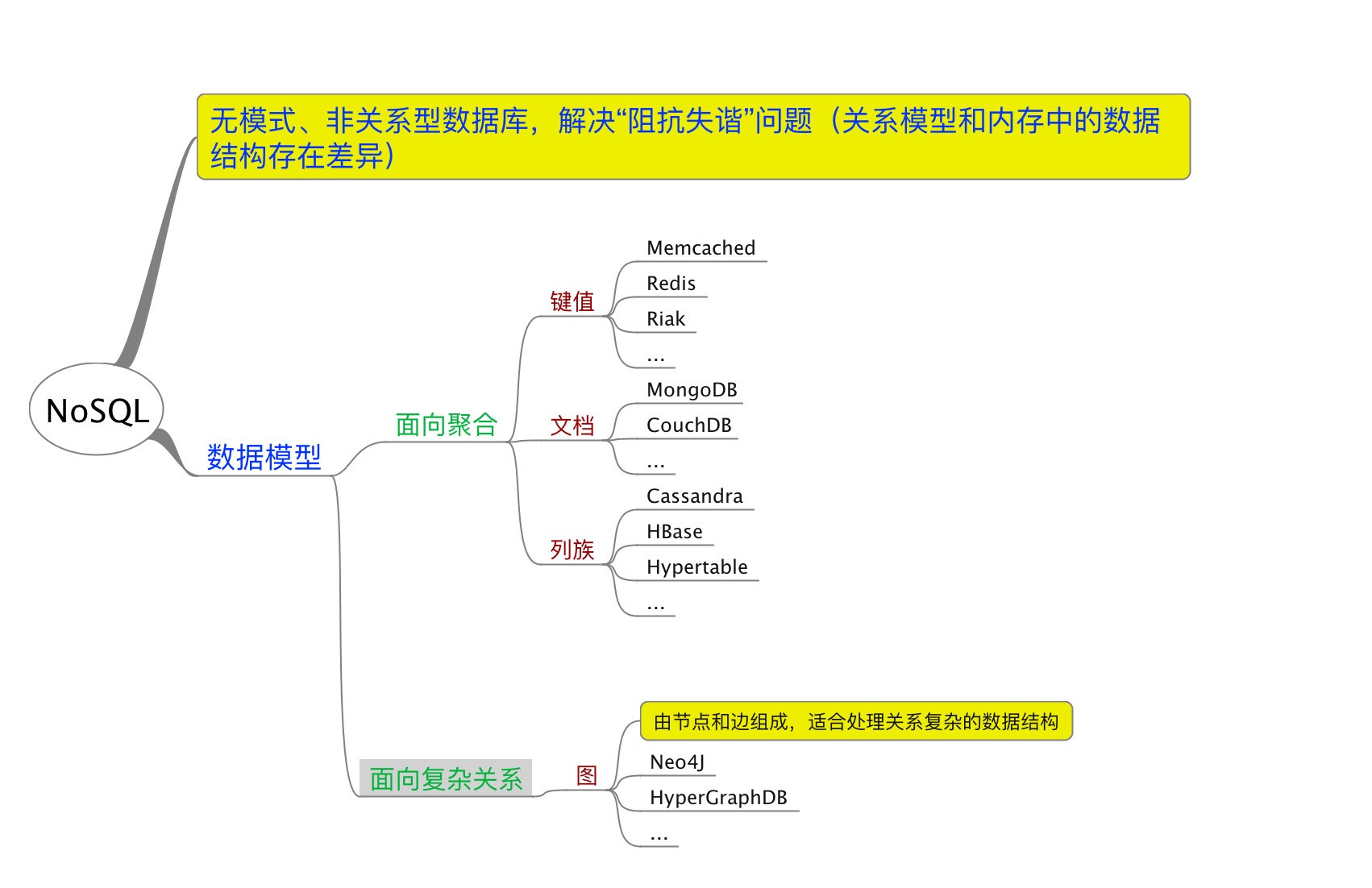
NoSQL数据库的数据模型有2种:面向聚合的数据模型、面向复杂关系的数据模型。
键值、文档、列族类型的NoSQL数据库都属于面向聚合的数据模型。
而“图”数据库则是一个异类,它比关系型数据库更擅长处理复杂的关系,补充了关系型数据库的另外一个不足之处。
它们都是无模式的数据库,可以随意新增字段,然而用户在使用数据时,通常还是要遵循一套隐式模式。
面向聚合的数据库对于复杂查询的支持比不上关系型数据库,它通常是用不同的方式重组主聚合的数据,以计算出各种“物化视图”。计算过程一般通过“map-reduce”来实现。
分布式模型
在不需要分布数据就能应对时,总应选用“单一服务器”方案。
数据分布的路径有2种:复制(replication)、分片(sharding) 。
2者是“正交的” ,可单独使用,也可以结合使用。
由简至繁的顺序如下:
- 单一服务器
- 分片
- 主从复制
- 对等复制
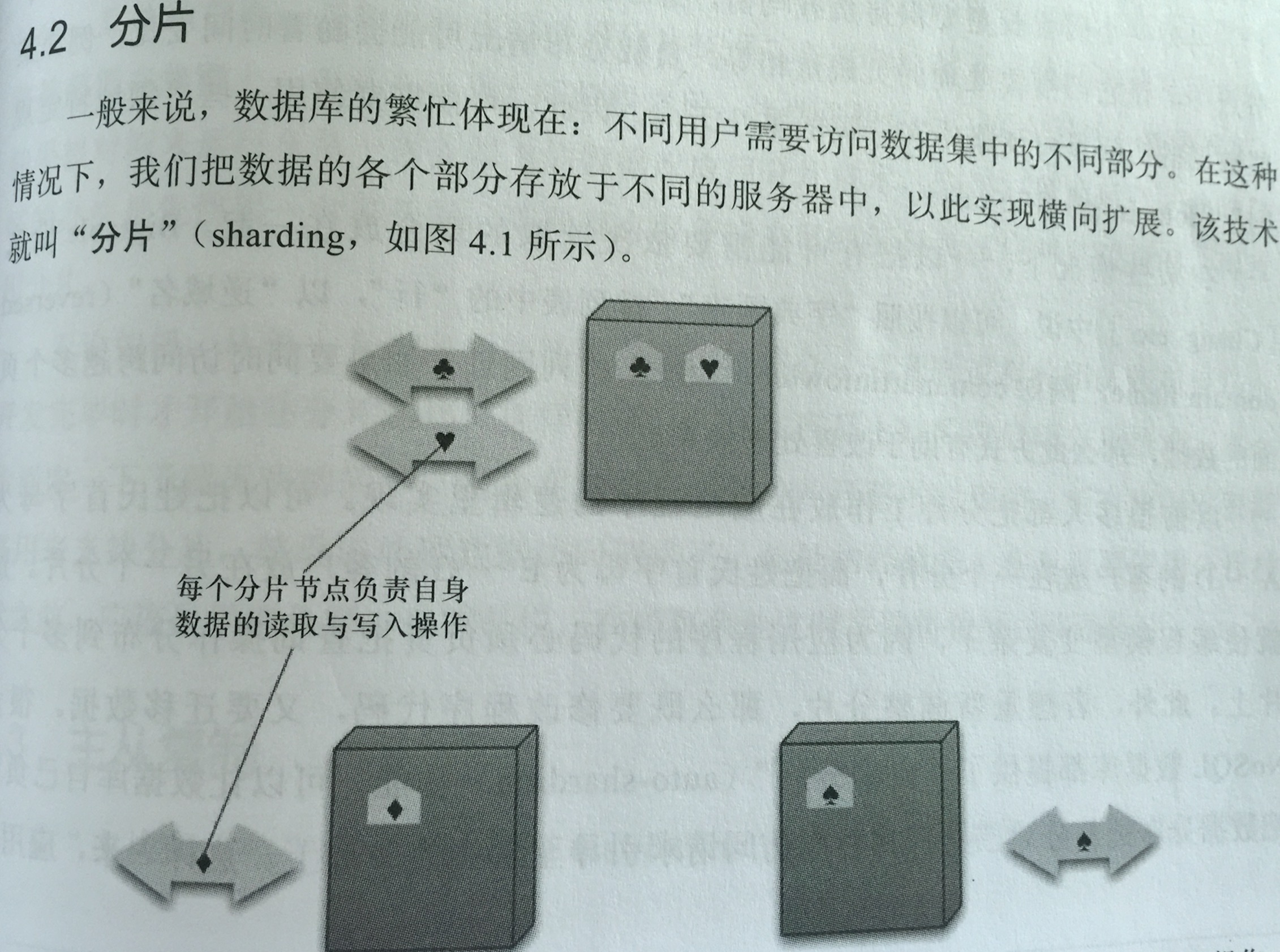
分片
把数据分部分存放在不同服务器中,以此实现横向扩张,这种技术就叫“分片”。
分片同时提高来读取和写入的效率,但也有可能降低数据库的错误恢复能力。
主从复制
主持复制通常是经过“投票”的方法来选定一个“主节点”,“主节点”负责写入数据,通过复制的方式把数据同步到“从节点”,“从节点”复制数据的读取。
主从复制适合需要频繁读取数据的情况,它增强来读取操作的故障恢复能力。
但其缺点是,在数据同步的过程中,容易带来数据的不一致性.
对等复制
对等复制没有“主节点”的概念,所有的节点对等的写入和读取。
但它也存在数据的不一致性的问题。
版本戳
版本戳可以由计数器、GUID、内容哈希码、时间戳来实现,或者组合其中几种来实现。
通过版本戳可以有效的检测并发冲突问题。
映射-从简
map-reduce是一种集群上执行并发计算的模式
“映射”任务从聚合中读取数据,将之缩减为相关键值对。
“从简”任务将“映射”任务生成的许多相同关键字的值简化为一个输出值。
它们之间可以通过“管道”的方式来组合,通过“物化视图”来存储招的计算结果。
键值数据库
键值数据库(key-value)是一张简单的哈希表,所有数据库访问都通过主键来操作。
流行的键值数据库有:Riak,Redis、Memcached等。。
适用场合
- session信息
- 用户配置信息
- 购物车数据
不适用场合
- 数据间关系
- 含有多项操作的事务
- 查询数据
- 操作关键字集合
文档数据库
文档数据库以“文档”为主要概念,存储格式可以是XML、JSON、BSON等。
流行的文档数据库有: MongoDB、CouchDB等
它有一个键值数据库没有的好处: 可以直接查询文档中的数据,不需要先根据关键字获取整个文档。
适用场合
- 事件记录
- CMS与Blog
- 网站分析与实时分析
- 电子商务
不适用场合
- 包含多项操作的复杂事务
- 查询持续变化的聚合结构
列族数据库
列族数据库可以存储关键字及其映射值,并且可以把值分成多个列族,让每个列族代表一张数据映射表。
流行的列族数据库有: Cassandra、HBase等
适用场合
- 事件记录
- CMS与Blog
- 计数器
- 限期使用
不适用场合
- 查询模式多变的场景
图数据库
图数据库可以存放实体及实体间的关系,实体也叫“节点”,它们之间的关系也叫“边”。
流行的图数据库有:Neo4J、HyperGraphDB 等
适用场合
- 互联数据
- 基于位置的服务
- 推荐引擎
不适用场合
- 属性多变的场景
混合持久化
不同的数据库用来解决不同的问题,只用一种数据库引擎的时代已经过去。